AI voice generator and text-to-speech tool
Generate natural-sounding voiceovers using Synthesia's AI voice generator. No need for microphones, voice actors, or audio recordings.
- Generate AI voices in 140+ languages
- 230+ talking AI avatars
- Amazingly realistic and lifelike
Rated 4.7/5 on G2
Trusted by over 50,000 companies

What's the difference between an AI voice generator and traditional text-to-speech?
Text-to-speech software
Text-to-speech technology takes written text and converts it into speech using a computer-generated voice.
These synthetic voices can sometimes sound robotic or monotonous. TTS is commonly used for navigation systems, screen readers, and automated phone systems.
A text-to-speech tool has limited capabilities in terms of naturalness and expressiveness, and may not provide the nuanced intonations and emotions required for sophisticated audio production.
Users often prefer using AI voice generators for more emotive content.
AI voice generator
An AI voice generator, on the other hand, uses advanced AI algorithms trained on natural human voices to produce ultra-realistic AI voices and AI narration.
AI voice technology doesn’t simply convert text to speech; it creates human-like voices for video voiceovers.
AI voiceover generation tools often offer a variety of voice options, languages, and accents, allowing users to select voices that align with their target audience.
This technology is particularly valuable for businesses looking to produce high-quality voiceovers for videos, e-learning, and more.
Realistic AI voices for diverse use cases
Create training videos with natural-sounding AI voices in minutes, instead of weeks. Replace boring text-based training manuals with engaging videos.

Generate educational content with lifelike AI voices to increase learners' engagement. Create lectures with voiceovers in just a few clicks.

Improve your customer experience and satisfaction by transforming your knowledge base articles into short videos with natural AI voices.

Keep your employees and stakeholders engaged with natural-sounding and realistic internal communication and corporate videos.

Create professional-looking explainer videos, product videos, and brand videos without hiring a video production or recording studio.


Key features of the AI text-to-voice generator
Choose from 1000+ AI voices in 140+ languages
Create content for a global audience in multiple languages. Choose from 400+ high-quality voices in 140+ languages and accents.
Effortlessly clone your voice
Create your own AI voice using Synthesia's built-in voice cloning feature. Generate your own voiceovers without any equipment.
Create AI text-to-speech videos in minutes
Generate natural-sounding AI voiceovers and videos with AI avatars. With Synthesia's AI video editor, there's no need for cameras or microphones.
Translate TTS voiceovers and videos in 1 click
With Synthesia's integrated video translation tool, effortlessly adapt any video and audio content into 70+ languages in just one click.
Collaborate with your team in one place
Save time by working on your AI voice generation projects with multiple team members, all in one place.
Generate scripts with AI and convert to speech
Use the built-in AI script generator to create an engaging video script and transform it into an AI voice over in one place.


AI voice generators in 140+ languages







Generate high-quality AI voices with Synthesia
Natural-sounding speech
Synthesia's text-to-voice generator produces the most advanced AI voices in multiple languages and accents, while also allowing you to correct the pronunciation if needed.
Easy-to-use interface
Synthesia is an intuitive platform that offers AI voice acting and converts text to video seamlessly. All without the need for complex editing tools.
Automated closed captions
Improve your video's accessibility by automatically generating closed captions that are synced with your AI voiceover and video.
4 benefits of AI text-to-speech tools

- Consistent quality of voiceovers in contrast to traditional voiceover methods
- Instant results: generate voice content using advanced AI voices in seconds.
- Improved accessibility for those using screen readers
- Cost reduction: users can save up to 50% compared to traditional voiceover methods.
How to create the best AI voiceover using Synthesia
See how you can use Synthesia's powerful features to turn text into audio and video in a matter of minutes.
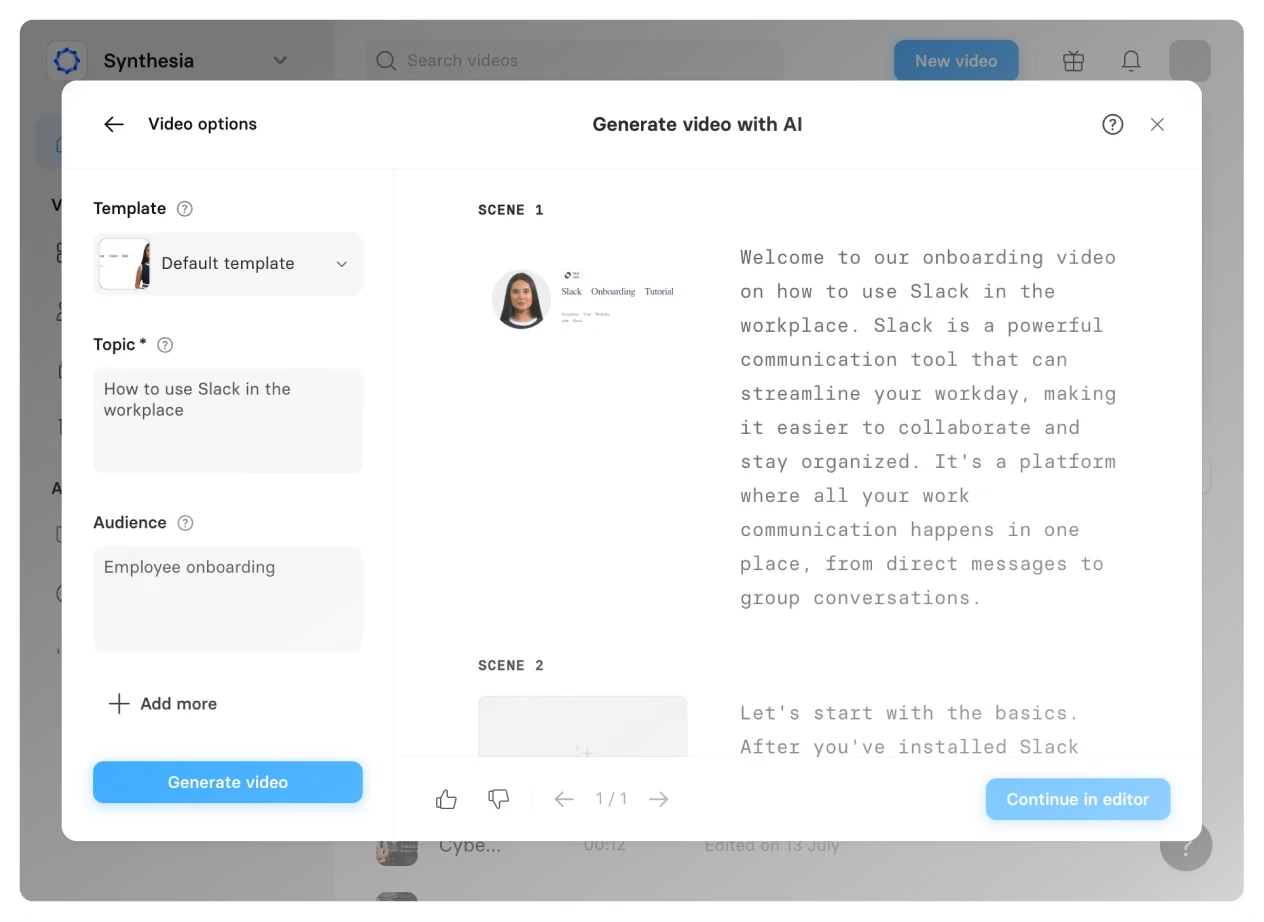
Create an account
Sign up for Synthesia and create a new video.
Paste your text
Paste your text or generate a script with our AI script generator.
Choose an AI voice
Choose from 1000+ realistic AI voices. The AI text-to-voice generator will automatically convert the written text into speech.
Add an AI narrator
Make the text-to-speech voiceover stand out by adding a realistic avatar to narrate your text.
Adjust and edit
Personalize your text-to-speech video with stock photos or your own images, videos, audio files, shapes, and more.
Generate a video with voiceover
That's it! Now you can download, stream, embed, and share your voiceover videos with your audience on social media, YouTube, and other platforms.


Pain points solved by AI voice generation

Faster video creation
"Synthesia’s AI voiceovers sold me instantly. They give us the ability to pivot and create video content much faster than before"

No actors - no costs
"Relying on external agencies and hiring voiceover actors in multiple language was extremely costly. So it would either mean stretching the budget or no video at all."

Speed, simplicity and ease
"We can record anytime and anywhere with greater speed, simplicity, and ease. It not only optimizes work schedules but also increases productivity and benefits the quality of our educational materials."


AI safety & security
People first, always. We prioritize the secure, safe, and ethical use of artificial intelligence in our product development processes.
SOC 2 & GDPR compliant
Our data handling practices, systems, and processes have been independently audited and certified.
Trust & Safety team
Our Trust and Safety team ensures the protection of your data and the ethical application of AI.
Content moderation policy
We use a combination of human and AI moderation processes to safeguard our community from bad actors.
AI policy and regulations
We actively engage with regulatory bodies and champion the formulation of robust AI policies and regulations.



12 reasons why Synthesia is the best AI voice generator
Effortless AI narration
Tired of spending hours searching for the right voice-acting professionals? Struggling with self-recording? Our voice generation tool automates the narration process. Just paste or type your text, and watch as it's transformed into a natural human voice in just a few minutes.
Save time and money
Traditional voice recording is time-consuming and expensive. With AI there's no need to hire voice actors or buy expensive equipment. You reduce your voiceover costs by 50% and cut 95% of your video production time.
1000+ different voices
Whether you need a friendly and engaging voice for YouTube videos or professional voiceovers for explainer videos, Synthesia has a vast library of voice options, accents, and languages. Choose the perfect voice to resonate with your target audience.
Personalization at your fingertips
Make each narration unique with customizable options. Adjust the pronunciation to make your AI-generated text-to-speech voice sound just right.
Authentic and expressive
How good can an AI-generated voiceover sound? AI voices are trained on human speech, so they sound natural and expressive, providing a human touch that engages listeners and keeps them captivated.
Global reach
Break language barriers effortlessly with multilingual AI audio files. Reach a wider audience without the hassle of hiring multilingual voice actors.
Maintain consistent quality
Create content with a consistent brand voice. Establish a recognizable human-like voice that resonates with your audience.
Enhance accessibility
Make your content more inclusive by providing AI audio versions for visually impaired individuals and those who prefer auditory consumption. Synthesia also automatically generates closed captions for all videos.
Voice cloning
Clone your own voice to provide consistent and instantly recognizable AI audio across your content. With voice cloning, you can maintain a cohesive brand identity and a familiar tone that resonates with your audience.
Make changes with ease
With Synthesia you can simply make changes to the text and update the video without the need to record a voiceover from scratch. This is a valuable feature to keep your content updated at all times without spending additional time or resources.
Create content with the best AI voices
Leverage our AI voice software to produce content that captivates viewers. Enrich your projects with high-quality, synthetic voices for enhanced clarity and realism.
Take advantage of world-class research
Our text-to-speech tools, powered by the latest developments in generative AI voice technology, transform written content into lifelike speech, setting a new standard for audio experiences.
All your AI voice questions answered
What is an AI voice?
An AI voice is a synthetic voice generated by artificial intelligence, designed to mimic human speech patterns and tones.
How do I create an AI voice?
AI voices can be utilized by accessing voice generation platforms or APIs, inputting desired text, and selecting the preferred voice type or accent. Once processed, the AI outputs the text in audio format, which can then be saved, shared, or integrated into applications.
What is an AI voice generator?
An AI voice generator is software that converts written text into humanlike voices. It can be customized to different speech styles, ages, genders, and accents and offers an easy translation to over 120 languages.
Which is the best AI voice generator?
Synthesia is best AI voice generator (according to G2 reviews). It combines the most advanced AI voices with state-of-the-art generative video capabilities that allow users to generate realistic videos with voiceovers in minutes!
Are there any free AI voice generators?
Try Synthesia's free AI voice generator to test out its voice generation capabilities. Simply pick a voice, type in your script into the best free AI text-to-speech tool, and press 'Play' to hear the result.
Can I make an AI of my own voice?
Yes! You can create your own AI voice using Synthesia's built-in voice cloning feature. Then, your own AI voice will appear in your Synthesia account, ready to be paired up with any avatar.
What is the AI voice generator everyone is using?
According to G2 reviews, the best AI voice generator on the market is Synthesia. The text-to-speech tool allows users to generate both ultra-realistic AI voices and videos with human-like AI avatars to narrate the voiceover. All without the use of video editing or recording equipment.
How to use an AI voice generator?
- Type in your script into the text-to-speech tool or use an AI script generator
- Choose an AI voice
- Hit play to generate
- Download the voiceover
How can I make an AI voiceover?
To make an AI text-to-speech voiceover, go to Synthesia's text-to-speech video creator and follow these steps:
- Sign up for Synthesia
- Create a new video by choosing a template
- Paste your video script and choose an AI voice to generate the text-to-speech voiceover
- Edit the video by adding an AI avatar, images, music, videos, and more
- Generate and download your video
What is the most realistic AI voice generator?
The best free text-to-speech generator is Synthesia, as voted by 1500+ reviewers on G2. Users can choose from 1000+ AI voices with a wide range of emotions, tones, accents, and languages and pair the voice with an AI avatar for an even more lifelike performance.
13 best AI voice generators of 2025
What is the best AI text-to-speech software? Let's compare the 13 best paid & free AI voice generators on the market.
| AI voice generator | Pros | Cons | Starting plan | Free plan | Voice cloning | Languages |
|---|---|---|---|---|---|---|
Synthesia | 1. Extensive library of languages and accents. 2. Ability to create videos with an AI presenter. 3. Preview before generating. | 1. Time-consuming avatar and voice matching. 2. Pronunciation issues with some words. | $18/month | Free plan + Free demo | Yes | 140+ |
Murf.ai | 1. Easy to use. 2. Adjustable pitch and speed. 3. Realistic voices. | 1. Interface responsiveness issues. 2. Limited high-quality voices to English. 3. Relatively expensive. | $19/month | Free plan | Yes | 20+ |
Listnr | 1. Large collection of voices and languages. 2. Multiple pricing plans. 3. Voice cloning feature coming soon. | 1. Large collection of voices and languages. 2. Multiple pricing plans. 3. Voice cloning feature coming soon. | $5/month | Free plan | Yes | 142+ |
Speechelo | 1. Different tones available. 2. Adjustable voices. 3. 60-day money-back guarantee. | 1. No free demo. 2. Only 24 languages supported. 3. Salesy website. | $47/month | No | No | 24+ |
Descript Overdub | 1. Ability to clone your own voice. 2. Testable on their website. 3. Can make videos with AI voices. | 1. Supports only English. 2. Complicated pricing for audio and video. 3. Difficult navigation for new users. | $12/month | Free plan | yes | 1 |
WellSaid Labs | 1. Studio of AI talent. 2. Hyper-realistic AI voices. 3. Pioneering in text-to-speech quality. | 1. May be expensive. 2. Limited to English and a few accents. 3. Some emotional expression issues. | $44/month | Free trial | yes | 1 |
Play.ht | 1. Supports 142 languages. 2. Voice cloning feature. 3. Extensive voice selection. | 1. Less diverse non-English options. 2. Limited free version. 3. Pricing may be high for some. | $31.20/month | Free plan | yes | 142 |
Lovo | 1. Custom pronunciation rules. 2. Voice cloning. 3. 100+ languages supported. | 1. Pronunciation/inflection issues. 2. Limited features in free plan. | $24/month | Free 14-day trial | yes | 100+ |
Replica Studios | 1. Intuitive interface. 2. Multiple export formats. 3. Central script and line management. | 1. Learning curve for advanced features. 2. Higher price for premium features. | $10/month | First month free | No | 1 |
Speechki | 1. Tailored for audiobook production. 2. Extensive language range. 3. Control over speech elements. | 1. Learning curve for new users. 2. Limited support for niche accents. 3. Premium features cost extra. | $7.19/month | Free plan | Yes | 80 |
ElevenLabs | 1. User-friendly interface. 2. Extensive control over voice qualities. 3. Wide voice collection. | 1. Advanced feature complexity. 2. Focus on major languages for high-quality options. 3. Costly premium access. | $5/month | Free plan | Yes | 29 |
TikTok | 1. Inclusive and wide-reaching. 2. New form of entertainment. 3. Built-in text-to-speech feature. | 1. Primarily for entertainment, not professional use. 2. Limited customization compared to dedicated tools. | Free | Free | No | 1 |