Going bigger and faster on AI video with NVIDIA’s Blackwell GPUs in Google Cloud

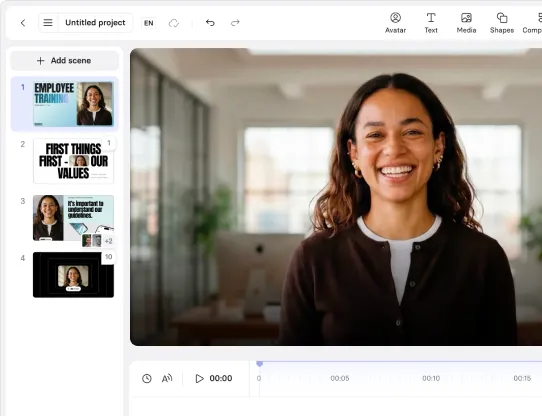
Create AI videos with 240+ avatars in 160+ languages
At Synthesia, we orchestrate complex multimodal AI systems that combine models for speech synthesis, facial animation, and natural language processing. Today, we want to offer a glimpse into how we became the first company in the world to train our AI video models using NVIDIA’s Blackwell GPUs on Google Cloud, and the improvements we’re making to our multi-cloud setup powered by NVIDIA hardware and software to help our customers create better videos faster in Synthesia.
Building a resilient, accessible and scalable infrastructure is important for the growth of our company.
Let’s start with accessibility. We train our models and put them in production in a multi-cloud environment, with data centers based primarily in Europe. We’re encouraged by recent efforts by governments in the UK and EU to work with hyperscalers and build more AI data centers locally equipped with latest-generation GPUs, as that would allow us to grow faster.
Our research teams are also scaling fast — more users leads to more demand for dev environments and cluster capacity. We’re also supporting more diverse use cases now, which naturally calls for different compute profiles. As iteration cycles speed up, having access to multiple cloud providers and high-end NVIDIA GPUs gives us the added flexibility to scale and provision resources more efficiently.
Thirdly, our model sizes are increasing as we push for higher quality. EXPRESS-1 was our first foray into building a diffusion model and we’re now training EXPRESS-2, an even larger diffusion model based on a transformer architecture. The significant increase in model size that comes with this architecture demands a new class of training compute which can handle more scale and more efficiency.
Until recently, we relied on NVIDIA Hopper-class GPUs to train our models. But over the past few weeks, we’ve been working to evaluate the performance increase of training EXPRESS-2 on the new and even more powerful A4 Virtual Machine (VM), powered by NVIDIA’s B200 GPUs. The results so far are encouraging: during initial trials, we've achieved a 40% performance improvement compared to previous training runs using H200 GPUs, and we were able to scale that further to 70% for a larger version of our state of the art model that’s currently under development. We achieved these performance improvements “out-of-the-box”, without investing significant amounts of time in doing B200-specific software optimizations, which leaves us plenty of space to drive the performance further. We’re now evaluating migrating our entire clusters to Blackwell GPUs, including our training cluster in Google Cloud and inference setup in AWS.
The video below, featuring my AI avatar, shows the performance increase alongside the visual improvements of a fine-tuned EXPRESS-2 running on Google Cloud’s A4 VM with B200 GPUs:
Optimizing AI model training is crucial to our continued innovation and we rely on several NVIDIA libraries and tools to improve our training infrastructure. Our specialized training tech stack leverages NCCL (NVIDIA Collective Communications Library) to ensure highly efficient GPU communication, enabling flexibility as we manage different NCCL versions tailored to various compute configurations.
Profiling and optimization are essential parts of our workflow, and NVIDIA Nsight has proven invaluable. It allows our team of model optimizers to precisely identify and enhance performance bottlenecks, directly leading to these remarkable improvements.
Furthermore, NVIDIA's Data Center GPU Manager (DCGM) plays a crucial role in our operations. It provides deep insights and fine-grained monitoring, even down to individual training jobs, ensuring we're constantly maximizing GPU efficiency and effectiveness.
Finally, the latest EXPRESS-2 avatars available to our customers today are deployed using NVIDIA’s Dynamo-Triton for inference which offers us flexibility and enables us to maximise GPU utilization through NVIDIA’s optimized inference engine, while also giving our engineers and researchers a unified interface for developing our state-of-the-art models.
We're proud of our team's continuous drive toward enhancing performance and scalability and close collaboration with NVIDIA and Google Cloud. Stay tuned for more updates as we continue pushing the boundaries of what's possible with generative AI.
Peter Hill is CTO at Synthesia and a veteran tech and product leader. Formerly CEO and CPO at Wildlife Studios, he spent nearly 25 years at Amazon and AWS, leading teams behind Kindle, Fire, Alexa, and services like Amazon Connect and WorkSpaces.