Express-2 is Synthesia’s next chapter for full-body, expressive AI avatars

Create AI videos with 240+ avatars in 160+ languages
Today, we’re diving deeper into Express-2, our new video and voice engine for AI avatars that pairs state-of-the-art voice cloning with a diffusion transformer (DiT) model designed to create full-body avatars that gesture like professional speakers. Thanks to Express-2, our new avatars combine facial expressions and lip sync with natural hand and body gestures, which makes it easier for viewers to understand and follow the context of the video.
Express-2 has been optimized for realism, control, and reliability at scale, generating 1080p, 30fps avatar videos of arbitrary length; the engine is built from two tightly-connected parts:
- Express-Voice: our proprietary in-context learning sub-system that instantly clones a voice, preserving identity, accent, and expressiveness without any fine-tuning. In blind tests with 100 native English-speaking evaluators across 17 diverse accents, Express-Voice was rated highest for matching the original speaker’s identity, rhythm and accent.
- Express-Video: an avatar animation and rendering sub-system architected on a video stack that translates speech into natural gestures, facial dynamics, and photorealistic frames through three coordinated models: Express-Animate (co-speech motion generation), Express-Eval (audio-motion alignment), and Express-Render (30fps video generation at 1080p).
A quick peek inside Express-2
Here’s how Express-2 works:
- Express-Voice: produces an audio readout of a given script. Express-Animate then uses the audio track to generate anatomically accurate, temporally coherent gestures driven purely by audio, decoupling motion from appearance so each can be improved independently.
- Express-Eval: A CLIP-like model trained on paired audio-motion data, scores alignment to pick the best motion candidate at inference.
- Express-Render: Synthesizes photorealistic frames, including fine facial movements, with robust identity consistency for long sequences.
To meet production needs, we distilled Express-Render to two diffusion steps, enabling practical generation speeds, with a faster Express-Render-Turbo on the way.
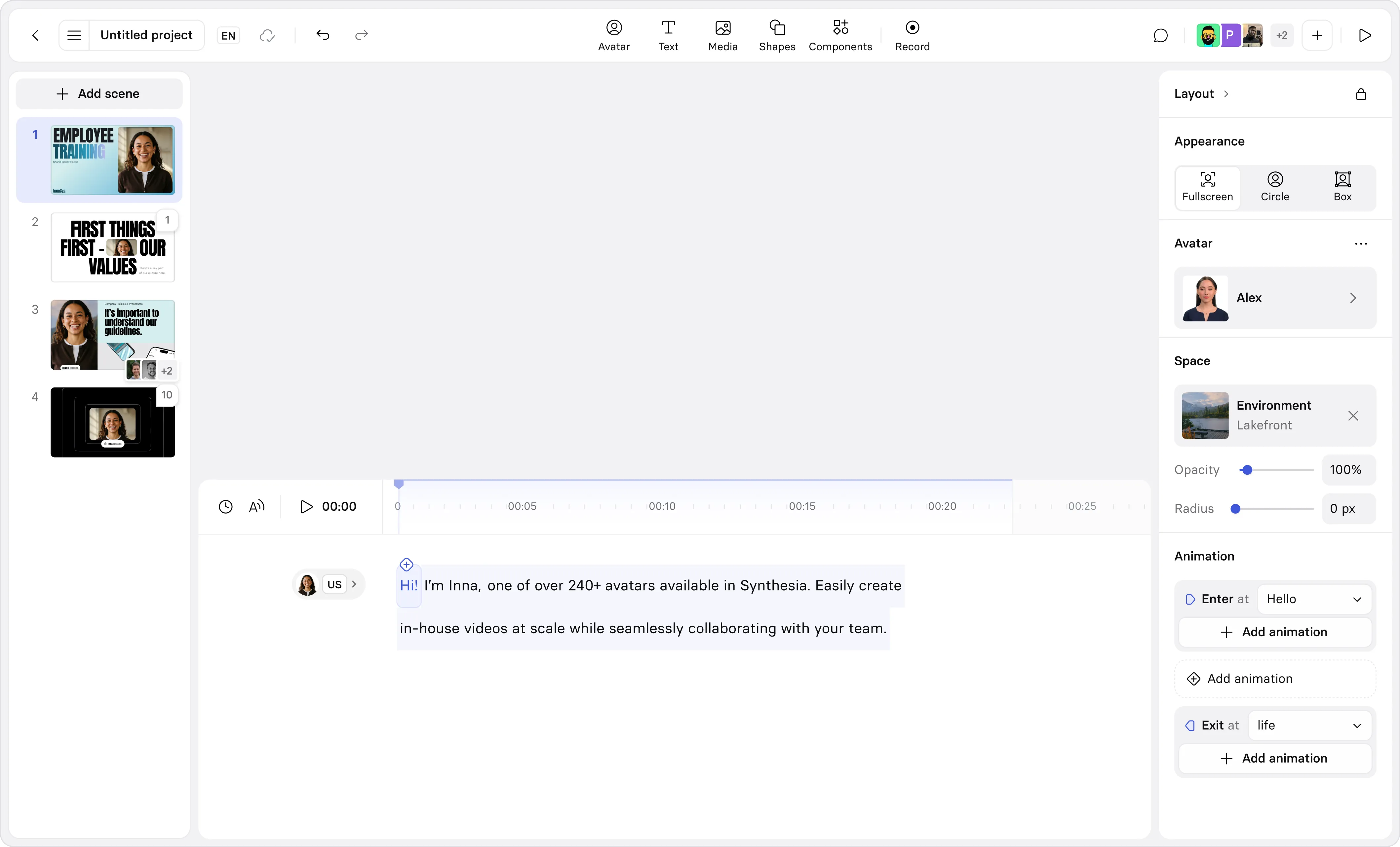
For creators, Express-2 also adds control levers: you can vary the seed for different takes, adjust temporal diversity for more/less movement, and tune performance intensity. You can also switch camera framings without changing the audio.
Instant, accented voice cloning
Express-Voice preserves the nuances and speech patterns of any voice, from regional accent to delivery, instantly and without adaptation steps.
Under the hood, a two-stage transformer (autoregressive + non-autoregressive, ~800M parameters each) operates directly on graphemes and is conditioned on reference audio (no fixed speaker embedding).
We’ve used Descript’s residual vector-quantized tokenizer, curated training data to cover a wide range of accents (including open corpora like YODAS and LibriLight), and evaluated with objective metrics such as WavLM (speaker similarity) and emotion2vec (emotional similarity).
Most importantly for customers, Express-Voice is now our default text-to-speech sub-system that drives the avatar’s performance, as we’ve unified voice, lipsync, and body language into one video and voice engine built entirely by Synthesia.Unlike other generative AI tools that have length limitations, Express-2 offers unprecedented quality without compromise: you get 1080p at 30fps video as an output, with consistent identity and natural co-speech gestures. With no limit on video duration, Express-2 delivers human-like performances that are highly engaging, leading to long-form videos with AI avatars that deliver information in an instructional and entertaining way. While Express-1 avatars brought expressiveness to the content made on our platform, Express-2 will make content more engaging to watch. Studies and real-world case studies have shown that higher engagement rates are drive understanding, making Express-2 especially valuable for skill development in large organizations.
Why this matters for enterprises
Unlike other generative AI tools that have length limitations, Express-2 offers unprecedented quality without compromise: you get 1080p at 30fps video as an output, with consistent identity and natural co-speech gestures. With no limit on video duration, Express-2 delivers human-like performances that are highly engaging, leading to long-form videos with AI avatars that deliver information in an instructional and entertaining way.
While Express-1 avatars brought expressiveness to the content made on our platform, Express-2 will make content more engaging to watch. Studies and real-world case studies have shown that higher engagement rates are drive understanding, making Express-2 especially valuable for skill development in large organizations.
Express-2 also introduces new creative controls, allowing you the ability to and pick camera angles to create more dynamic and engaging, YouTube-style videos. On the audio side, you can pick between several styles of the same voice, allowing you to manually adjust the voiceover to the performance you want to get. For example, you can pick the Excited option for marketing videos or choose Neutral for customer support scenarios.
Lastly, the progress we’ve made with distilled rendering means we can maintain a similar throughput in video generation despite the significant increase in quality, with further acceleration in the pipeline. In real terms, you should see similar generation times even though your videos will get more sophisticated and feature-rich.
Built on responsible AI Governance principles from day one
Synthesia is used by over 80% of the Fortune 100. We’re continuously adding features that allow enterprise companies to create and share videos safely and securely at scale, and we’re keeping our promise to build with a people-first approach. For example, we make it impossible to clone a real person without their consent - enforced with controls and verification.
We also moderate content at creation under robust policies, continuously red-team our systems, and make our approach transparent via our AI Governance portal. These safeguards carry through Express-2 and will continue to be updated as we introduce new features.
If you’re a paying Synthesia customer and want to bring human-quality performance to your videos at the speed your business moves, we’d love you to try out Express-2 today.
Peter Hill is CTO at Synthesia and a veteran tech and product leader. Formerly CEO and CPO at Wildlife Studios, he spent nearly 25 years at Amazon and AWS, leading teams behind Kindle, Fire, Alexa, and services like Amazon Connect and WorkSpaces.