Free AI voice generator
Generate natural-sounding voiceovers using Synthesia's AI voice generator. No need for microphones, voice actors, or audio recordings.
Trusted by over 50,000 companies
Generate realistic AI voices from text
Create natural, studio-quality voiceovers in 160+ languages that turn any script into ready-to-use audio in minutes.
Generate 1000+ voices in any language
- Voices for any use case that fit training, sales, support, and more
- Switch languages and accents instantly across 160+ options
- Match tone and style to your brand in every video
Effortlessly clone your voice
- Create a voice that sounds like you without recording every time
- Keep your voice consistent across every video and team
- Scale content fast without re-recording or extra effort
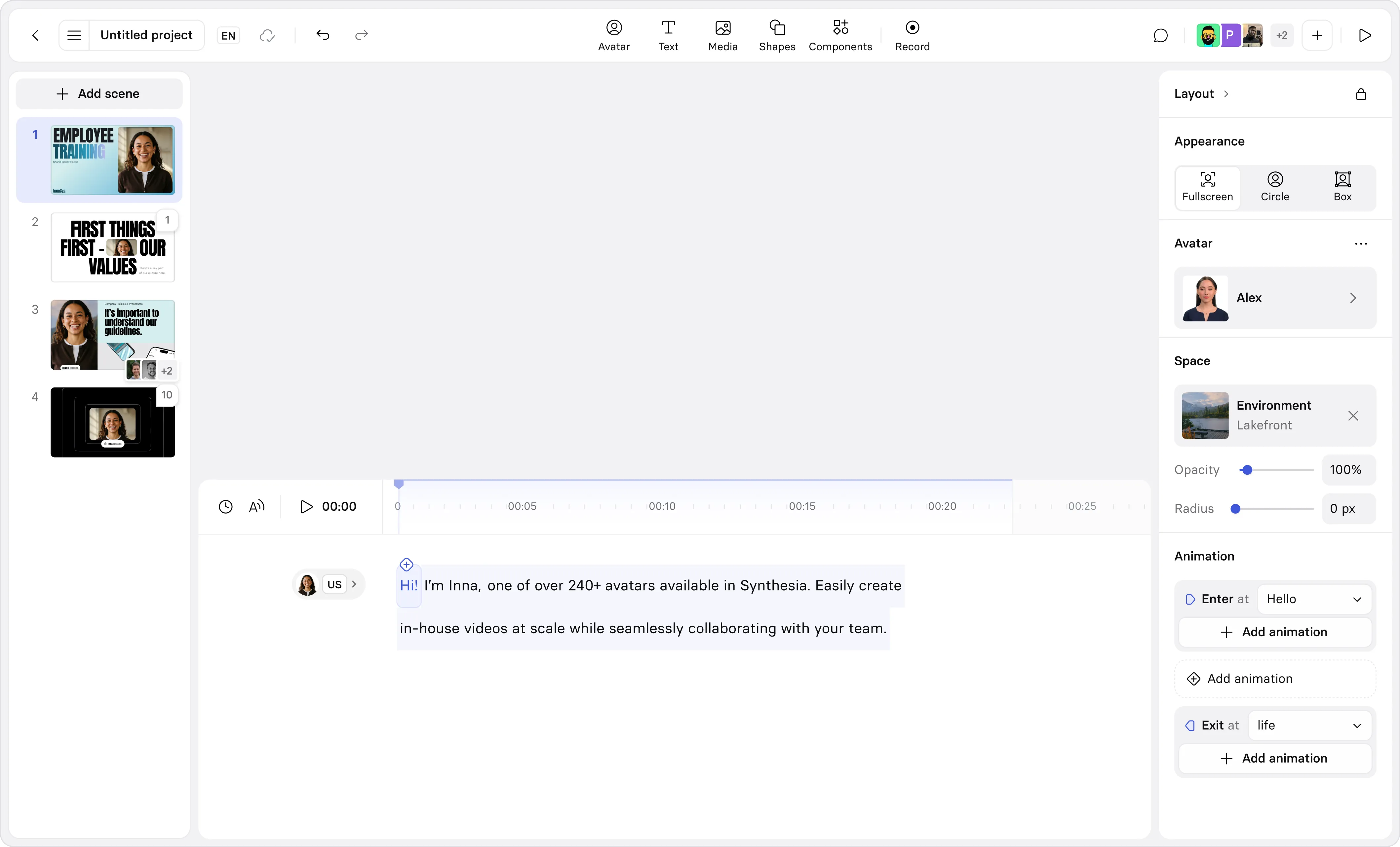
Seamlessly integrate voices with videos




- Turn your scripts into presenter-led videos in minutes
- Choose from 240+ avatars that match your audience
- Create videos fast without a camera or microphone
Realistic AI voices for any use case
Education
Turn slides, lectures, and study materials into clear, engaging voiceovers that make complex topics easier to understand and retain. Create consistent audio for lessons, summaries, and revision content that students can listen to anytime, anywhere.
Training
Deliver consistent, scalable training voiceovers for courses, onboarding, and internal enablement without relying on recordings. Update content quickly, localise training across teams, and ensure every employee gets the same high-quality learning experience.
Marketing
Create high-quality voiceovers for ads, explainers, and landing page videos quickly and affordably. Test different messages, scale campaigns across channels, and produce polished audio without studios, voice actors, or long turnaround times.
How to generate your own AI voice clone
Create your account
To clone your voice, you’ll need a Synthesia Enterprise plan.
Record your voice
Find a quiet spot, open the “Voices” tab, select “New voice,” and follow the on-screen steps to record.
Create with your new AI voice
Use your AI generated voice to create fully customized videos in Synthesia.


Explore our range of AI voices








Save time and reduce costs with AI voice generation

Faster video creation
"Synthesia’s AI voiceovers sold me instantly. They give us the ability to pivot and create video content much faster than before"

No actors - no costs
"Relying on external agencies and hiring voiceover actors in multiple language was extremely costly. So it would either mean stretching the budget or no video at all."

Speed, simplicity and ease
"We can record anytime and anywhere with greater speed, simplicity, and ease. It not only optimizes work schedules but also increases productivity and benefits the quality of our educational materials."

Frequently asked questions about AI voice generation
What is an AI voice generator?
An AI voice generator is a tool that turns written text into natural-sounding speech using artificial intelligence. Instead of recording audio manually, you can generate voiceovers instantly in different languages, accents, and tones.
How does an AI voice generator work?
AI voice generators use advanced text-to-speech (TTS) models trained on human speech. You input your script, choose a voice, and the AI converts your text into realistic audio, capturing pronunciation, pacing, and tone automatically.
How do I create an AI voiceover?
Type or paste your text into the editor, choose your AI voice, and generate your audio in seconds. Download your file and use it anywhere you need.
Is Synthesia’s AI voice generator free to use?
Yes, you can try Synthesia’s AI voice generator for free. Paid plans unlock additional features like more voices, longer scripts, and advanced customization options.
Can I use the audio generated by Synthesia’s AI voice generator for commercial purposes?
Yes, you can use the generated audio for commercial purposes, including marketing, training, and content creation, as long as it complies with Synthesia’s terms of service.
How do I convert my script into an AI video?
Simply paste your script into Synthesia, choose an AI voice and avatar, and generate your video. Your voiceover will be automatically synced with the avatar, creating a professional video in minutes.
What languages does Synthesia support?
Synthesia supports 160+ languages and accents, allowing you to create voiceovers for global audiences and localise your content easily.
Can I make an AI of my own voice?
Yes! You can create your own AI voice using Synthesia’s built-in voice cloning feature. Your voice will appear in your account and can be used across videos and voiceovers, helping you create content that sounds uniquely like you at scale.
Not just an AI voice generator
Beyond turning text into realistic AI voices, Synthesia helps you scale production with powerful tools like the AI script generator, AI dubbing that perfectly translates and lip-syncs your video content in 140+ languages and accents, and a library of professional video templates designed for training, marketing, and more.
Need to convert a slide deck into a video? Use our PPT to video tool to save hours of editing. Synthesia has everything you need to create professional videos at scale all in one place.