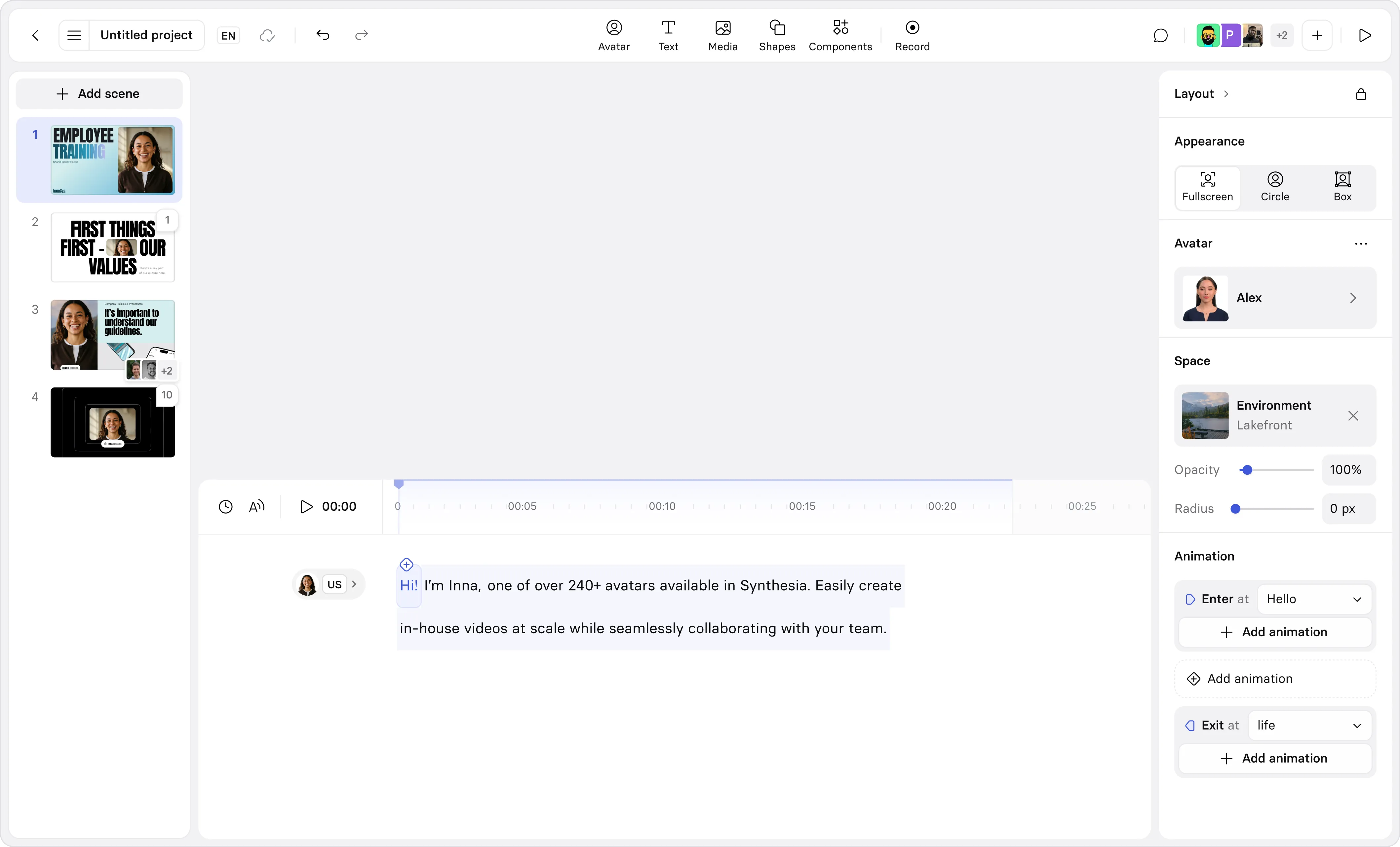
Synthesia’s new Avatars don’t just talk, they take action

Create AI videos with 240+ avatars in 160+ languages
Today, we’re taking a swing at one of the most familiar problems in AI video: while you can explain an idea with an AI Avatar, it’s often hard to show what’s happening with only a talking head.
Our new customizable Avatars are designed to help users generate both the explanation and the action inside the same editor. You pick an Avatar, describe the outfit and setting you want, and then prompt for a short action clip to illustrate the point right after it’s spoken. For teams producing industry-specific training, safety and operational procedures, or product explainers, the alternative has traditionally been to use a patchwork of tools: record a presenter, hunt down or shoot cutaway footage, and tie everything together in an editor.
This type of storytelling mirrors how you share information in real life: before jumping into action, you explain what is about to happen and then perform the action you just described. If you can do both the telling and the showing with the same Avatar, outfit, and background, viewers stay oriented and engaged longer because the narrative flows without visual whiplash. And because it’s all happening in one platform, you don’t need to juggle multiple software subscriptions just to get a 90-second explainer out the door.
At the heart of this new update are six new Avatars that gesture like professional speakers, powered by our Express-2 model. They’re built to deliver lines with natural movement so the “A-roll” of your video (the talk-to-camera explanation) looks and feels like a presenter on a real set, no matter the outfit or background you prompt. The twist is that those same Avatars can break from the podium and perform short, prompted actions as “B-roll,” so you can explain first and then show, just like you would in a live demo. And because the actions are prompt-based, you’re not limited to a fixed catalog of gestures.
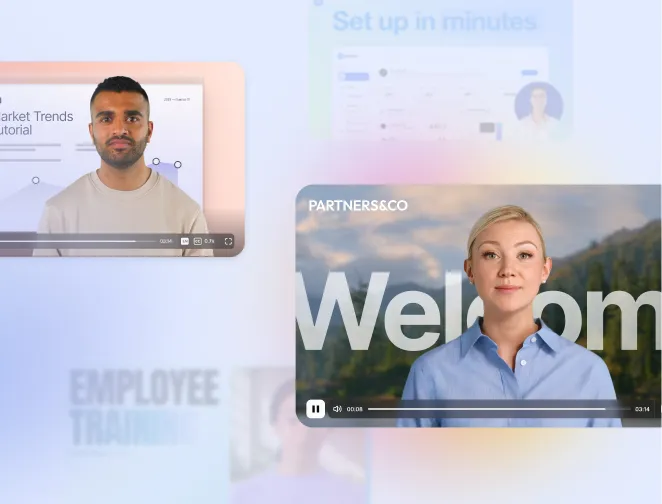
Customization is the other big upgrade that other competing solutions don’t offer. Instead of scrolling through preloaded wardrobe choices, you describe what the Avatar should wear in a text prompt (“high-vis vest and steel-toe boots,” “smart-casual blazer,” “hospital scrubs”) and the outfit updates to match. You can do the same for the environment: generate a background from a prompt, position the Avatar where you want in the frame, and save both the outfit and the space as reusable assets in your library. That means your sales team, your learning team, and your marketing team can all hit the same visual notes without rebuilding scenes from scratch.
The workflow of generating videos with the new Avatars is straightforward: you set up the A-roll with your customized Avatar and background, deliver the explanation, then cut to an action clip generated from a simple instruction (“walk to the whiteboard,” “place the device on the table,” “wave to camera”) before cutting back to the presenter.
By unifying A-roll and B-roll inside one place, we help you speed up scene creation, keep identities consistent across shots, and avoid the jarring jumps you sometimes get when you stitch together footage from different tools or stock libraries. There’s also a pre-baked spaces library so you can choose ready-made environments Avatars can interact with.
Once you create a few Avatars and spaces that you like, you can save both to your library, so recurring series such as weekly updates, onboarding modules, regional product walk-throughs keep a consistent look.
There’s also a policy tweak worth calling out. With the new Avatars, we’re updating our approach to content moderation so the businesses using these new Stock Avatars have more flexibility in what they make. In practice, videos generated with the customizable, action-capable Avatars will be reviewed under the same rules that govern Custom Avatars, rather than the more stringent policy historically applied to Stock Avatars. By making this change, we hope to open the door to more real-world scenarios, without dropping the core safety guardrails that already apply across our platform. For example, you couldn’t previously make videos for branding or business promotion purposes; with the new Avatars, that will now be possible.
We hope this update won’t just make Avatar videos look nicer, but it’ll reshape how teams storyboard from talking heads that tell you what’s happening to presenters who can also show it. We can’t wait to see how our customers push the limits with prompt engineering and discover new use cases for Synthesia.
Sundar Solai is a Product Manager at Synthesia, focused on AI video creation. With a background in computer science and statistics, he previously led YouTube’s autoplay algorithm and writes on AI topics, with work featured in TechCrunch.






.jpg)