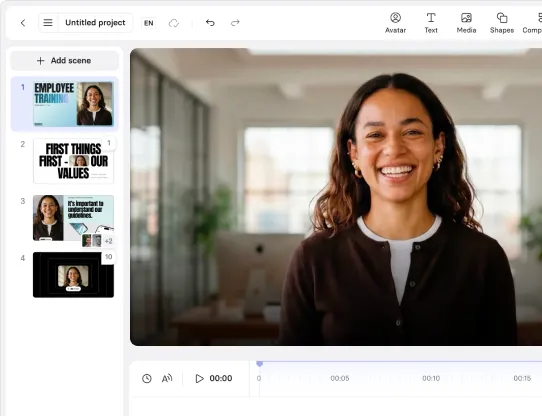
With Synthesia 3.0, the next era of video is here

Create AI videos with 240+ avatars in 160+ languages
For nearly a century, video has stayed the same. The format is still a one-way broadcast - recorded once and played back, over and over. Updating audio or visual elements isn’t easy, and you can’t interact, or measure your learning.
AI is about to change that. Instead of watching a static video, you’ll be able to interact in real time: talk to it, ask a question, or let the video ask you one. It will be highly personalized, with the full business context needed to train teams, and solve problems.
This is an entirely new media format, and today we’re excited to show you Synthesia 3.0, our AI video platform reimagined for the future of video, and some of the new products based on this vision.
Watch the video below for more information and read on for a quick breakdown of what’s new in Synthesia 3.0:
Introducing Video Agents
Video Agents are the first step toward video becoming a two-way conversation. They can be inserted at any point in your video - right in the Synthesia editor - to begin a real-time conversation with the viewer. And you can combine them with any other type of content, like static video and interactive scenes.
Video Agents can talk, listen, and act in real time, bringing a level of two-way interactivity that feels like a live conversation. They can run training sessions, screen job candidates, and even guide customers through learning experiences.
But the real breakthrough is in a new category of data. Video Agents operate with specific knowledge of your business. That means they can capture data in real time, feed it back into your systems, and take any action you assign. With a full understanding of your business, this functionality can easily automate and scale repetitive processes - giving your team time back to work on what matters most.
New features coming to the Synthesia platform
To make Video Agents possible, we’re bringing new capabilities across the entire Synthesia platform. Here’s an overview of the most significant updates:
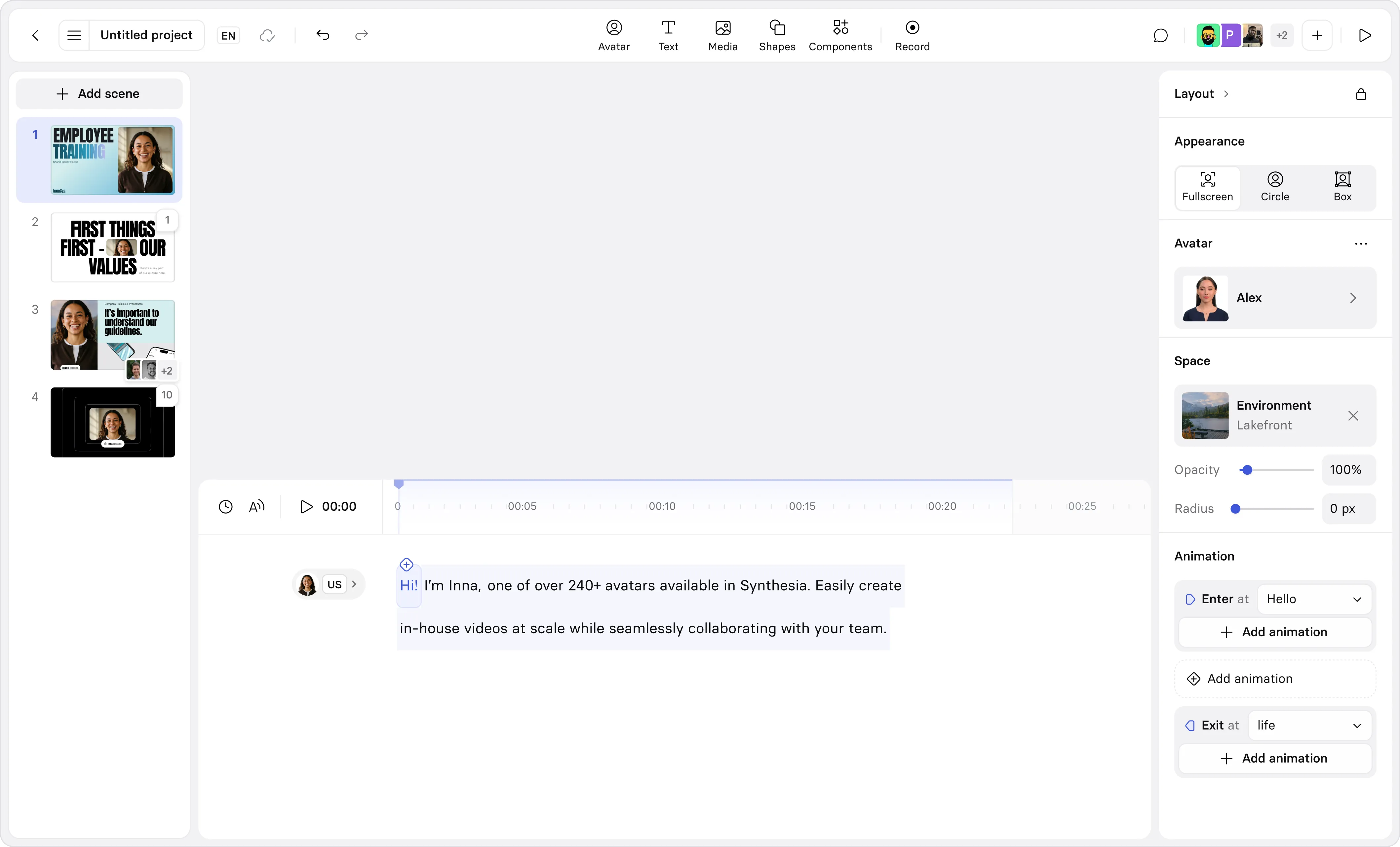
Avatars
Our new Express-2 avatars move and talk like professional speakers, with facial expressions, perfect lip sync, and natural hand and body gestures. We’re also adding many new features to our Avatar offering to allow for more customization:
You’ll now be able to create entirely new Avatars with a single prompt and place them into any environment. The lighting, depth, and perspective look so real that they blend in naturally, as if they were filmed on location.
You can prompt avatars in an office, at the beach or a construction site. You can also prompt an outfit to match that scene.
With Veo 3 integration, you can now prompt B-roll footage of your avatar demonstrating a task, or taking a specific action - like walking, driving, cooking, or anything else you can imagine.
You can create Personal Avatars more easily, AI versions that look and sound like you: rather than having to upload a video, you can just upload a single image, and have access to all the same customization features described above.
Voices
Our Express-Voice proprietary voice model creates your perfect voice clone in seconds, matching your tone and preserving your dialect, accent, and rhythm.
Interactivity
Get viewers to engage and take action with clickable video elements like call-to-actions and branching.
Dubbing
Translations with frame-accurate lip sync. Upload a video, and it will automatically translate into 30+ languages, and localize, with perfect voice and lip sync.
We’re also working on additional features that will be coming to Synthesia 3.0 in 2026:
Copilot is your very own professional video editor. It writes your script in seconds, connects to knowledge bases, and suggests visual elements.
Courses reimagines workplace learning by designing interactive experiences that combine Avatars, Video Agents, and Interactivity, and measure skill development.
The future of video
A century ago, the first TV broadcast transformed communication.
With Synthesia 3.0, we’re transforming it again.
In the future, we won’t be limited by the constraints of working with cameras. Soon, static video will be a relic of the past. We won’t just watch, we’ll interact. With every video, we’ll engage more, understand much better, and learn much faster.
At Synthesia, we’re incredibly excited to build this new video format with you.
Victor Riparbelli is co-founder of Synthesia, launched in 2017 with AI researchers. With a decade in tech entrepreneurship, he combines technical expertise and academic insight to advance AI video, focusing on ethical and responsible innovation.