Automating code security reviews with Claude: Mythos-level capabilities at lower cost

Create AI videos with 240+ avatars in 160+ languages
Coding agents are now involved in the majority of the code shipped at Synthesia. The volume of code changes has gone up but the time humans spend reading those changes has not. The practice of doing code security reviews is especially exposed to this pressure because it depends on careful analysis. To solve this, we’ve built an agent skill that approaches Mythos-levels of performance in uncovering complex security issues at a fraction of the cost of running such a model.
We previously wrote about scaling vulnerability management after issues have merged or shipped. We continued to scale our application security practices by providing security coverage at implementation time, before changes get merged, using coding agents.
The original idea was to build something engineers can self-serve to give their coding agent a feedback loop on the quality of the code it generates. We ended up building an agent skill that orchestrates an autonomous multi-agent security review pipeline, tuned to our stack and our common pitfalls.
This post describes how it's structured, the principles we settled on after iteration, and the operational realities that shaped the design.
Find security issues, make no mistakes.
The first thing anyone tries is the simplest one: pipe a diff into Claude, ask for security issues, share the findings. It can surface real issues, but it also surfaces a lot of noise.
The core failure mode of this approach is that a generic prompt produces generic output. You get an OWASP top-ten checklist applied to your code, regardless of what the code actually does.
This is because without specific guidance the agent has to build its own model of the code from scratch, and it has no obvious way to understand which abstractions in this codebase are trustworthy and which aren't.
Two problems compound from there: false positives and run-to-run variance. If the same diff produces different findings on different runs, the tool is hard to evaluate, hard to tune, and engineers will stop trusting the output.
A working AI security review system has to fix both. It has to be tuned to the codebase it's reviewing, and it has to be engineered against the noise.
We settled on three pillars:
- Build a map of the code flows where untrusted input can enter and trace the call paths that follow. This gives the agent a concrete starting point and stops it from wandering through unrelated files.
- Distill a dedicated security context so the agent reasons against our threat model, not whatever it picked up from CLAUDE.md.
- Wrap both in a pipeline that filters raw agent output into a small set of findings an engineer will actually trust.
The first two pillars close the gap between the agent and the code. The third closes the gap between raw findings and useful ones.
Building a map
The unlock was realizing that good security review is mostly orientation. When an agent starts with only a diff, it spends too much time wandering around exploring the code base to gather context. Different runs take different paths through the codebase, which makes the output more noisy and inconsistent (and increases cost).
We started by doing the orientation deterministically, before the actual hunt for vulnerabilities starts.
What we wanted in principle was full taint analysis: every path from source to sink, every transformation. In practice, packing deterministic taint analysis into a skill that works across our stack (Python, JavaScript, TypeScript, multiple frameworks) and runs on an engineer's laptop with minimal setup was too cumbersome. We wanted a frictionless self-serve experience, not a new platform.
So we flipped the problem: instead of doing full taint analysis we deterministically map any input entry point, then for each entry point we delegate mapping the code flow to smaller subagents.
There are two steps:
1) Enumerate entry points. We wrote Semgrep rules, one set per framework in our stack, that identify where untrusted input enters the application: HTTP route handlers, GraphQL resolvers, websocket endpoints, CLI commands, queue consumers. Entry points are where security risk concentrates, so finding them precisely is most of the orientation work. The rules are embedded in the skill and Semgrep is on every engineer's machine already, so we paid no install cost to add it. The skill always starts by running Semgrep against the code in scope.
2) Cartographer phase. For each entry point found, a small Haiku subagent (we call them Cartographers) traces the call graph through application code to the sinks it reaches: database, shell, filesystem, network, template. It's coarse taint analysis done by a cost-effective LLM: not perfect, but good enough. The output is a flat, factual map of entry point, path, and sinks.
This gives us a good-enough map of the code in scope without adding too many dependencies. With this we can now be precise with our prompting: "here is an entry point, here is what it reaches, find this kind of vulnerability on this code path." On a large codebase, this is the difference between an agent staying inside its scope and wandering through unrelated files polluting its context window.
Security Context
The second pillar was figuring out what kind of context helped the agent do the review. We ran some experiments and learned that code-generation context hurt security review quality, especially variance.
Files like CLAUDE.md, cursor rules, and repo-level coding instructions are written to help an agent complete a code generation task: follow conventions, trust existing abstractions, and fit the codebase. Security review needs the opposite prior: distrust abstractions, question conventions, and assume framework patterns can be misused.
We now keep the security context separate from the codegen context. The system reads SECURITY.md files distilled from our threat models, past bug patterns, and framework misuses we've already had to fix once.
What goes in those files is information that disambiguates findings: the tenant model and where the isolation boundary lives, the blessed authorization primitives so the reviewer recognizes drift, an ID risk taxonomy, explicit anti-false-positive notes for patterns that look wrong but aren't, and the historical vulnerability classes this piece of the codebase has actually shipped. None of it would be inferable from just reading the code in scope.
The delivery mechanism piggybacks on the agent harness's progressive discovery of AGENTS.md context files. When the reviewer opens a file deep in service/core/auth/, the nearest SECURITY.md loads automatically, scoped to that subsystem. The threat model isn't shoved into every prompt; it's loaded only when relevant to the code in scope.
With proper security context the variance of findings dropped: we consistently started finding the same issues across multiple runs, while sensibly reducing the number of issues discarded as false positives.
We will share more about our approach to build a security context in a future blog post.
The security review pipeline
The third pillar wraps the orientation work and turns vulnerability analysis output into findings an engineer can act on. This is where we did most of the engineering against false positives and run-to-run variance.
The skill orchestrates six phases. Each one after the first is delegated to subagents with a clear task and a model sized to that task, and produces a single artifact handed to the next phase. The main agent is only responsible for orchestration.
Engineers can self-serve by running:
/synthesia-security-review [scope]
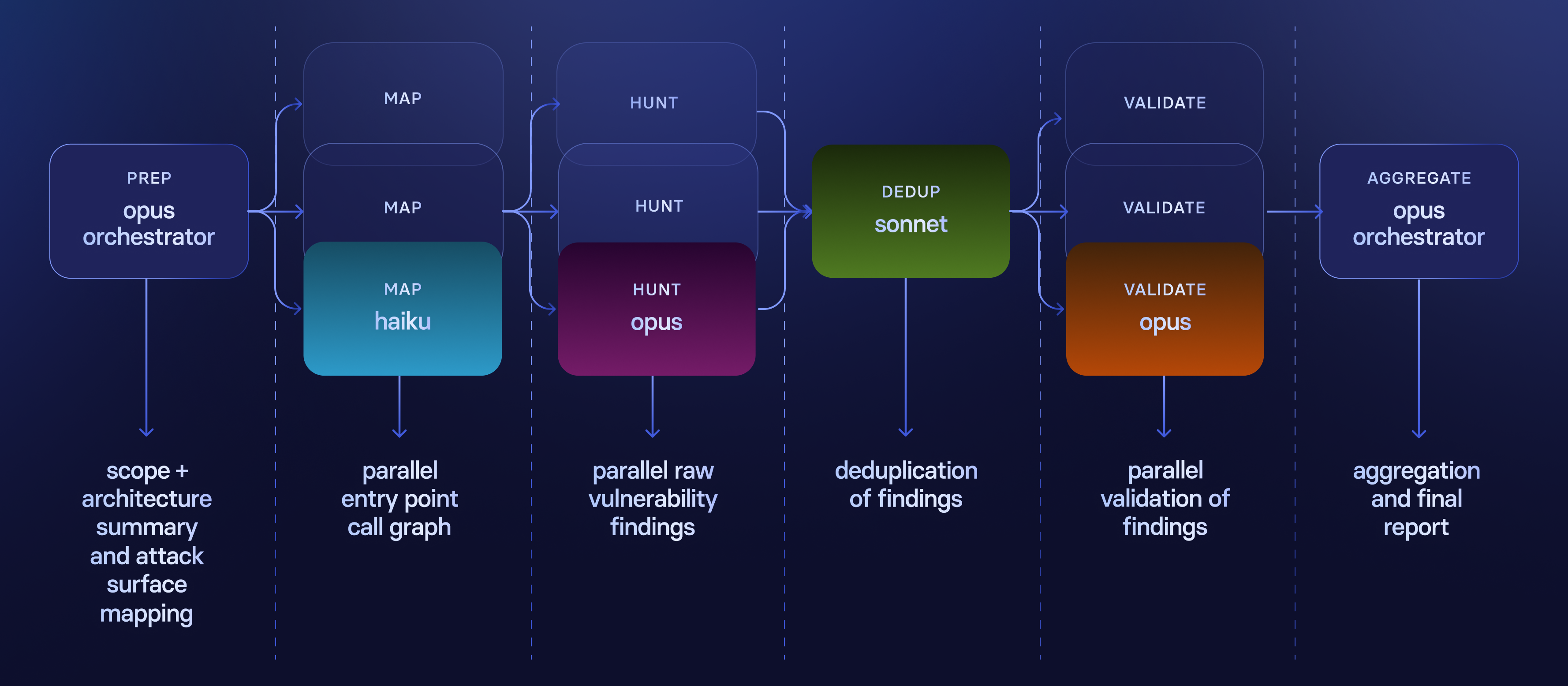
Step 1: Preparation. The main agent resolves the given scope (PR, staged changes, or path), detects the language, summarizes the architecture, and writes some high-level context in .security/architecture.md.
Original code-generation context is dropped if present, and the security-context layer is overlaid over the codebase.
Step 2: Build a Map. Map all entry points with Semgrep, then run one Haiku cartographer subagent per entry point in parallel. Each traces application-level paths from source to sinks and writes its segment of .security/attack-surface.md.
If Semgrep finds no entry points, we fall back to a single Sonnet subagent to identify untrusted input sources by reading the code. That output is also useful for learning whether we need to write additional Semgrep rules for future iterations.
Step 3: Hunting for Vulnerabilities. We give architecture.md and attack-surface.md to three subagents that run in parallel to find vulnerabilities. We call them Hunters.
Hunters are not prompted as specialized personas; they are tasked to find a specific class of vulnerability within a specific code path from the previous phase. We landed on running searches for injection, authorization, and business logic issues.
Each hunter follows a playbook:
- Goal: find exploitable vulnerabilities of $VULN_CLASS.
- Context:
- Read architecture.md for the list of files in scope and an architecture overview.
- Read attack-surface.md for entry points and call graphs.
- Step 1: Triage entry points.
- Scan the attack surface map and select entry points relevant to the $VULN_CLASS.
- Skip entry points that are not relevant.
- Step 2: Investigate.
- For every selected entry point, investigate the call graph and search for $VULN_CLASS issues.
- Flag everything plausible (we validate and dedup later).
- Step 3: Write each finding inside .security/<finding-id>.md.
Step 4: Deduplication. At this stage a single Sonnet pass reads all the findings and merges the ones with the same root cause.
We do deduplication before validation, because validation is one-agent-per-finding and therefore expensive.
Findings can overlap meaningfully (the same issue can appear in two hunters' output, despite their different focus). Deduping first means we don't pay to validate the same issue three times.
Step 5: Validate. One subagent per deduped finding, all running in parallel. Each one re-reads the code, checks whether the abuse scenario actually holds, and classifies the finding as a false or true positive. For true positives we also check whether it is realistically exploitable.
Validator agents are deliberately prompted to be stricter than hunters; their job is to push back. They follow this playbook:
- Step 1: Trace the code path.
- Step 2: Check for existing mitigations.
- Step 3: Assess exploitability.
- Step 4: Verify the risk rating.
- Step 5: Write the validation verdict in the finding file: false positive, confirmed likely, or confirmed unlikely, and why.
Step 6: Aggregate. After validation we discard false positives and low-impact findings without exploit paths. We rank what remains based on our internal guidance and write a final report for the end user in .security/FINDINGS.md.
At this point the review is done, the report is fed back to the user's coding agent, and they can just command a "fix this".
Two design choices are worth pulling out, because they're where most of the engineering went:
Shared context files, not inlined prompts. Subagents read .security/architecture.md and .security/attack-surface.md themselves. Task context is passed between subagents via files. This makes them easy to prompt and gives us a paper trail to inspect each run.
Right-sized models per phase. The expensive models are reserved for the two phases where judgment actually matters: hunting and validation. Most of the cost-vs-quality tradeoff in an agent pipeline is decided by how narrow we can make each step's task, not by which model we pick. As such we don’t really need to wait for Mythos or new frontier models with cybersecurity training if the whole orchestration is sound, but once they become available we can easily switch over the critical phases.
How we built this
Agentic systems are non-deterministic. The same skill, run twice on the same code, will not produce identical findings. Every change you make to a prompt, a phase, or a model assignment lands on top of inherent run-to-run variance, and "it looked better this time" is not evidence of anything.
We started by building something very simple and iterated over it following a simple benchmarking strategy.
We keep a reference codebase from our own product with a known set of issues. Every iteration of the skill (a new prompt, a new phase, a model swap, a rule change) runs against it. We track three dimensions: cost, wall time, and the findings produced. We run each iteration multiple times to get a basic read on variance, not just a single point estimate.
The rule is: no dimension is allowed to regress. A change that improves recall but doubles cost doesn't ship. A change that looks better on one run but is unstable across three doesn't ship. A change that finds new true positives but reintroduces a false positive class we'd already eliminated doesn't ship.
This isn't sophisticated. It's just refusing to make decisions on vibes. It's a useful habit we've adopted for iterating on agentic systems, not because the methodology is clever, but because the alternative, which is "this run looked good," is how we end up spending too much time making something subtly worse.
The numbers
One last step of the skill reports the results back to the security team so we can analyze how it behaves over time.
We group runs into cohorts by scope size (number of lines of code changed). For each cohort we measure:
- Cost per review. Average API spend per review.
- Review duration. End-to-end wall time of the skill run.
- Valid findings, broken down by severity.
- Discarded findings. The number of deduped findings rejected as unlikely or false positive.
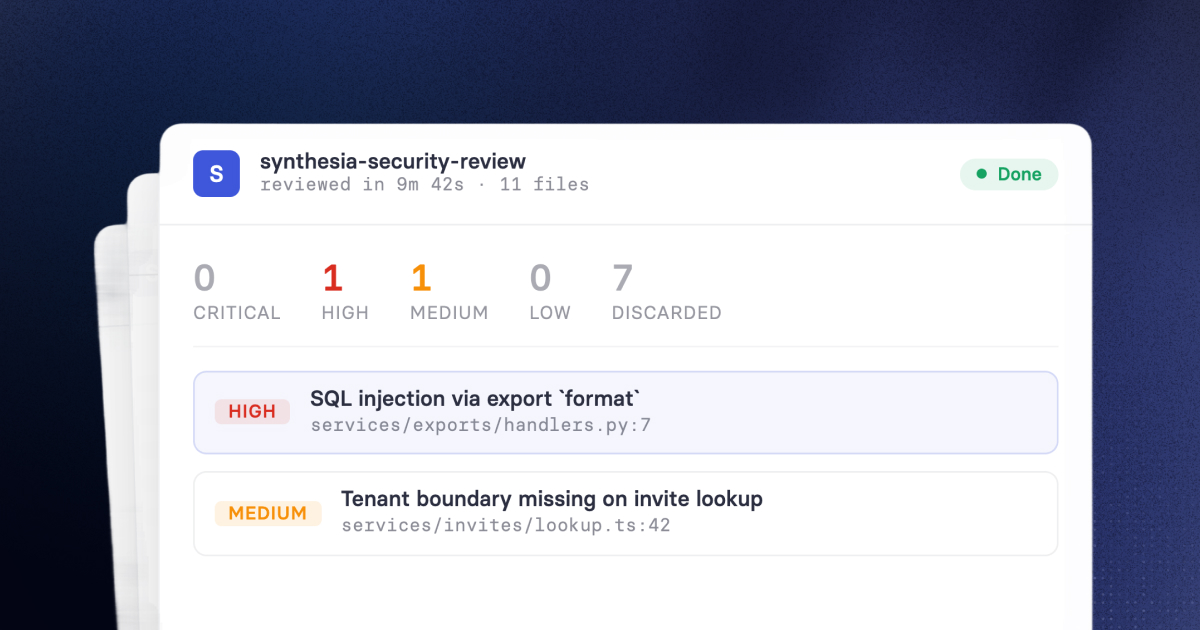
These are our numbers so far:

A few things stand out:
The pipeline discards about 60% of what the hunters surface. Across all reviews, validators and aggregators together throw away roughly three findings for every five the hunters produce. That's the operational story mentioned earlier: hunters flag anything plausible by design, and most of the engineering in the pipeline is what filters their output down to something safe to act on.
The cost-per-actionable-finding is in the low single digits. A large review averages $6.15 and surfaces about 2 valid findings, which works out to roughly $2.70 per finding an engineer actually reads. A small review averages $2.72 for about one finding. We don't think these numbers are particularly impressive on their own. The point is that they're cheap enough that running unattended on every pull request won't trigger a budget conversation.
The severity mix is realistic. Critical findings show up in roughly one review out of thirty. Most of the actionable output is in the medium and high bands, which is what we'd expect from a system reviewing code that already passes the rest of our pre-merge checks. We watched closely for a "flood of criticals" failure mode in the early iterations and didn't see it.
From self-serve to CI, and what's next
We built the skill self-serve first with a clear value proposition: any engineer, any time, can run a security review on the code they're about to push, without involving the security team.
Predictably, adoption was slow and concentrated. The strongest adopters were the already security-minded engineers who needed it the least. The engineers we most wanted to reach (fast-moving, agent-assisted, shipping a high volume of generated code) were hard to convert.
So we moved it into CI, attached to every pull request, but non-blocking. The cost per review made this affordable and the design of the pipeline made it possible to run unattended in a remote sandbox. Findings are posted on the PR for the author to triage and into the Security backlog for further processing.
Non-blocking is a deliberate choice given the slowness of a full review run: despite parallelizing where possible, a review still takes nearly ten minutes on average.
This is a best-effort system. If the review lands a comment on a pull request before it gets merged and it's acted on: great.
For everything else, the bet we're making is post-merge patching: when the skill identifies findings on a merged PR, another agentic system opens a follow-up PR with a proposed fix, ready for the original author to review. This treats the speed limit honestly (security review is slower than the merge) and converts a finding from a piece of feedback the engineer has to act on into a piece of work that's already half done. We'll report back on how it goes.
Build your own
You can replicate our approach. What's worth copying are the design principles:
- Encode your attack surface deterministically. Write the entry-point rules for your tech stack. Do this to prevent the agents from wandering around and keep them focused on the scope.
- Split the pipeline into narrow phases and right-size the model at each one. Save the expensive models for the phases where raw intelligence actually matters.
- Build the dedup and validation phases before you tune the hunters. Low false positive rates come from the pipeline downstream of the hunter, not from a cleverer hunter prompt.
- Keep your security context separate from your codegen context. They have opposite priors. Sharing them degrades both.
- Measure every iteration on a reference codebase. Cost, time, findings, across multiple runs. The non-determinism of agents is the hard part of building one of these, and the only honest answer is discipline about what counts as evidence.
Point a coding agent at this post and have it draft a version of this skill tuned to your stack, then iterate against your own benchmarks. Make no mistakes!
Gianluca Brindisi is a Security Engineer at Synthesia, leading AI security and building secure-by-default products. With 10+ years’ experience in tech scale-ups and cloud infrastructure, he focuses on scaling security through AI-driven tooling.