Scaling Vulnerability Management with AI: What Actually Worked


Create AI videos with 240+ avatars in 160+ languages
As the product grows and engineers are adopting AI tooling, the security team has more and more code to protect from vulnerabilities.
Our tools generate a lot of security signals and our bottleneck is scale more than ever: find the real issues fast, validate them, and get fixes shipped inside our SLAs.
Validation and fixes are the slowest steps: they both require analyzing a feature code across multiple repositories we might not always be too familiar with, and eventually pulling the original developers into the security problem, forcing them to context switch and adding to their cognitive load.
Starting last summer we decided to make things better, following two principles:
- Minimize developer cognitive load for security work
- Minimize security team toil: if we can automate it, we should
We started experimenting whether coding agents could speed up validation and fixes and ended up building the foundation of an AI powered vulnerability management program.
Our first target was code vulnerabilities, since they require the least amount of context. We addressed static analysis (SAST) and supply chain (SCA) findings, because the inflow volume was the highest.
Shrink the backlog
To start, we removed stale repositories from the attack surface.
We run automations to detect stale repos, detach CI/CD, and set them to read-only. When we archive a repo, we stop tracking its vulnerabilities because the code no longer runs.
At the beginning we rolled this out in batches to address the long tail. We archived about a third of our repos and closed about 60% of findings. We confirmed with owners before archiving, and we reclaimed storage by deleting old build artifacts like container images.
Next, we grounded our efforts into how we tier repositories by business risk:
- Does it touch customer data?
- Does it ship the core product?
- Is it directly exposed to customers?
Yes to all: Tier 1. At least one yes: Tier 2. All no: Tier 3.
Tiering adds business context to validation and prioritization and is a proxy metric for potential impact.
Automate triage
With a smaller set of repos, we still had a significant influx of findings across SAST and SCA. Our hypothesis was that most did not need a human review.
We built nightly workflows that apply layered triage rules. Each layer encodes a policy decision.
Severity-based triage
Findings under a certain risk threshold are auto-triaged as accepted. With a small team, we have to be conscious of resources. Low-risk findings in lower-tier repos slow us down if they pile up in the backlog. Making this policy explicit and automated freed the team to focus on what matters.
This reduced the open SAST issues influx by about 29%.
AI-assisted false positive detection
Our main SAST provider Semgrep introduced a feature called Assistant that flags findings as likely true or false positives with AI. We benchmarked it for a while and found out that with the immediate context of the codebase analyzed, the assistant was flagging obvious false positive almost always correctly. Once we had built an appropriate level of trust in the tool, we integrated it so any finding flagged as a false positive is automatically closed.
We noticed that the Assistant biases toward true positives when context is missing, which fits our risk tolerance: we'd rather manually close a false positive than miss a real one.
We also use the assistant input to benchmark the Semgrep rules we use in our main policies. Noisy rules get reviewed and either tuned or removed. High signal rules earn more trust.
Supply chain analysis
For SCA findings, we combine EPSS scores, dependency reachability analysis, and system tiering as a proxy for business impact. An unreachable dependency in a Tier 3 repo is not the same as a reachable, high-EPSS vulnerability in a Tier 1 repo handling customer data.
This layer auto-triages about 89% of SCA findings, leaving the cases that warrant human review.
The result
After all layers run:
SAST weekly (71% Auto triaged)
Severity-based triage: 29%
Semgrep false positive detection: 16%
Auto resolved (archived, code changes): 26%
Remaining for human review: 29%
SCA weekly (89% Auto triaged)
EPSS, Reachability and Business Impact: 89%
Remaning for human review: 11%Each morning, our automations posts a summary in Slack: processed findings by workflow and severity and a breakdown of the rules performance. It's our quick check that the system behaved as expected.
Validate and fix faster
What survives the funnel are high and critical findings that are likely real, in repos that matter. These need validation and fixes.
The traditional cycle is slow. A security engineer reviews the finding, understands the codebase, determines if it's real, writes guidance, files a ticket. Then a developer context-switches to implement a fix and weeks pass before it ships.
We turned to coding agents.
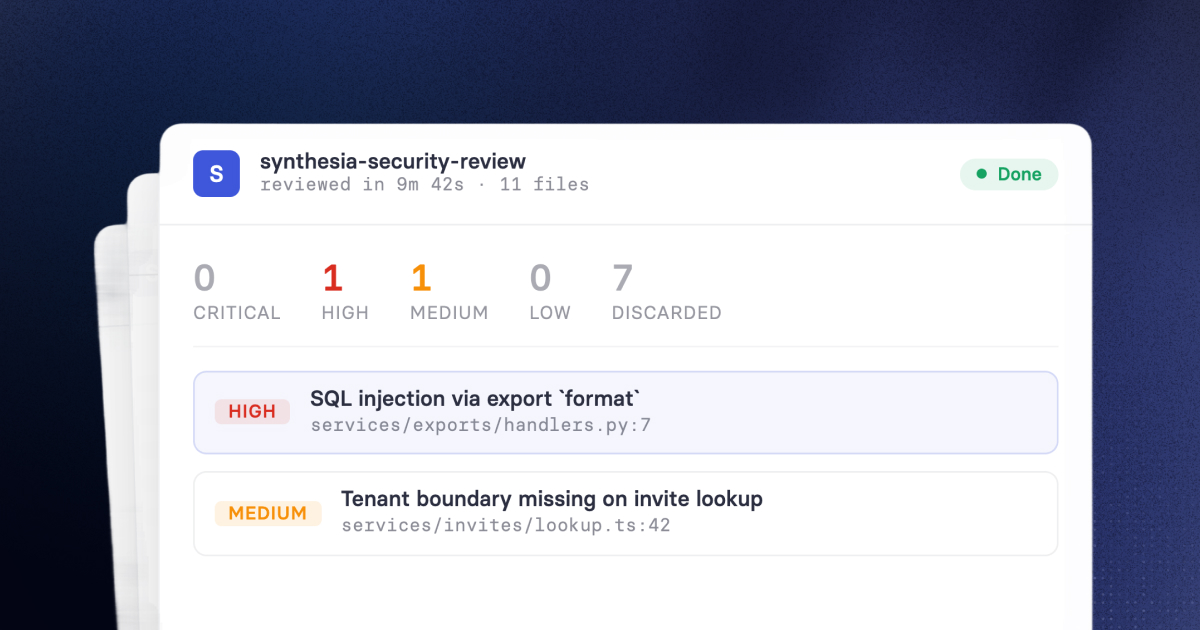
We built an agent orchestrator on top of Github workflows. As first thing we automatically turn critical findings into Github issues with structured context: links to code, Semgrep analysis, severity, and the triggering rule.
Validation
Upon issue creation another workflow spins up three independent coding agents to analyze the finding.
We set on three to reduce nondeterminism. It's an odd number by design: when agents disagree, the orchestrator makes a final call instead of deadlocking. As models improve, consensus is more common, but the multi-agent setup still catches confident wrong answers from a single agent.
Each agent analysis is summarized in the issue. If consensus is reached the issue is labeled true-positive or false-positive. False positives get closed right away with a note.
This system allow us to triage the remaining 29% of our SAST backlog automatically, with the following result:
SAST weekly (100% Auto triaged)
Severity-based triage: 29%
Semgrep false positive detection: 16%
Auto resolved (archived, code changes): 26%
Custom agent false positives: 18%
Custom agent true positives: 11%Fixes
For confirmed true positives, the true-positive label triggers an agent to create a branch, implement a secure fix, and open a pull request.
The PR enters the repo's normal review flow. Instead of starting from a security ticket and a blank editor, the developer now reviews a proposed fix with the vulnerability context already embedded. As the adoption of coding agents generates more PRs anyway, engineers already spend more time reviewing than writing. This meets them where they are.
Closing the loop
Twice a day, a workflow checks whether Semgrep recurring scans marked the finding as fixed (meaning the PR got merged), then closes the matching issue on Github. Open issues are still assigned to a security engineer who is responsible to follow up on the linked PR with the fix.
Humans stay in control
The workflow is label-driven. We started fully in control of when to start validation and when to generate a fix by manually triggering the workflows with specific label on the issues. As we grew confident we automated more.
What we learned
- Fast prototyping is key. We built this in less than a quarter, pioneering the use of terminal coding agents in the company, on top of Github workflows. The goal was to experiment and iterate fast, and GH workflows served us well as a prototype platform. It's been very successful and changed our perspective on what a small team can ship if we have the infra that enable fast iterations. The caveat: we still own maintenance.
- AI features from our tools help, but they fail in predictable ways. Every AI powered feature we looked at required evaluating its failure modes. For example Semgrep Assistant has been massively useful for false positive detection, but trusting it blindly on secondary analysis would have led us to overestimate risks. Use AI outputs as one signal among many, and add feedback loops that detect drift.
- Match automation to risk. Auto-triage low severity findings. Monitor AI driven closures. Keep a human gate before pushing fixes to critical repos. The cost of human attention should be proportional to the blast radius of getting it wrong.
- Observability is critical. Slack summaries, dashboards, rule tracking, audit logs for every automated decision. We invested as much in observability as in the automation itself.
Next steps
We found a pattern that work for us: aggressively triage the obvious automatically, create a ticket only for the important things, orchestrate deep validation and fixes with agents from it.
We see this as the base of our vulnerability management program and we are working to apply it beyond code and learn what amount of context is needed for agents to effectively validate and fix various type of security issues.
Gianluca Brindisi is a Security Engineer at Synthesia, leading AI security and building secure-by-default products. With 10+ years’ experience in tech scale-ups and cloud infrastructure, he focuses on scaling security through AI-driven tooling.