Security Context: Onboarding Agents to Your AppSec Team

Create AI videos with 240+ avatars in 160+ languages
For anyone in the Product Security or AppSec world, the last year has revealed a repeating pattern as teams experiment with AI agents for security review.
The code review agent is technically impressive, spots real issues, and references the right CWEs, but somehow still just misses the point.
- It assumes a new API endpoint is fine because it has basic auth in place, but it is completely out of line with your golden paths.
- It jumps up and down about amplification attacks that might cost you pennies even if exploited.
- It highlights a risk that everyone in the company is already aware of and accepted years ago.
The agent isn't wrong. It just lacks context.
Think About Your Last New Hire
When a strong senior security engineer joins your team, they aren't immediately productive. They need time to onboard.
Sure, they know how to read code. They understand how to spot vulnerabilities and have a solid handle on architectural best practices. All the fundamentals are there.
But for the first few weeks, and in some orgs even months, they still need help.
They're surprised by some legacy decision that seems bonkers, but makes sense for your org.
They're worried about specific threat actors or risks that were hugely important to their last company, but not yours.
They don’t yet know which services interact, which are crown jewels, and which are disposable.
Sound familiar? They don’t need to be smarter. They need context. For a human new hire, you've no doubt already done this:
- You give them the architecture overview
- You walk them through the threat model for the core product
- You tell them which risks are accepted and why
- You explain what "normal" looks like for your codebase; the patterns, the conventions, the expected auth flows
If we can’t expect human new hires to have this context, why do we assume AI agents will magically just "get it"?
We’re setting them up to find lots of issues and look impressive at first, but ultimately fail to add real value or help us scale.
What Do We Mean by Context?
When we started testing different AI agents, we all agreed that context was key. But we also weren’t entirely entirely sure what we meant by that.
Framing it like onboarding a human helped us quickly align on a few key areas.
.png)
1. Architectural Context
How does your system fit together? Is it one giant monolith, or are you fully committed to micro-services? Which surfaces are external-facing? Where is the trust boundary between services?
An AI agent reviewing a PR in isolation has no idea whether it's reviewing a public API endpoint exposed to the Internet, or a highly trusted internal service with service-to-service auth in place.
That simple context changes how findings are framed, solutions proposed, and risk scoring applied.
2. Code Patterns and Conventions
Ask any developer and if they're not embarrassed by at least one key area of the codebase they support, they've probably shipped too late.
Every codebase has stuff that's weird, things that are legacy, things that made sense at the time but now seem bonkers. Are all of those best practice from a security perspective? Unlikely.
But you've reviewed them before, they're known safe, and if a new feature uses them, it's likely going to be grand. But if a new feature doesn't follow them, that's worth an AI agent flagging.
3. Threat Models
"Your threat model isn't our threat model": often stated, but without this context, how would an AI agent know?
Threat models document your reasoning: the realistic attack scenarios for specific features or services, and, crucially, what you concluded the actual risk was.
That structured reasoning is exactly what an AI agent can use, if it has access to it.
4. Risk Appetite and Accepted Risks
Risk appetite varies by org. Are you handling highly sensitive or regulated customer data where a breach would be a death knell for the business? Are you processing billions of time-sensitive transactions and a likely DDoS target?
You need to tell an agent what you actively care about. Making your priorities explicit is what separates findings that are actionable from findings that are merely technically correct.
And of course, every mature AppSec function maintains a register of known risks it has consciously decided to live with.
An agent with no visibility of this will raise those issues every single time, burning trust with engineering teams and creating noise that buries real findings.
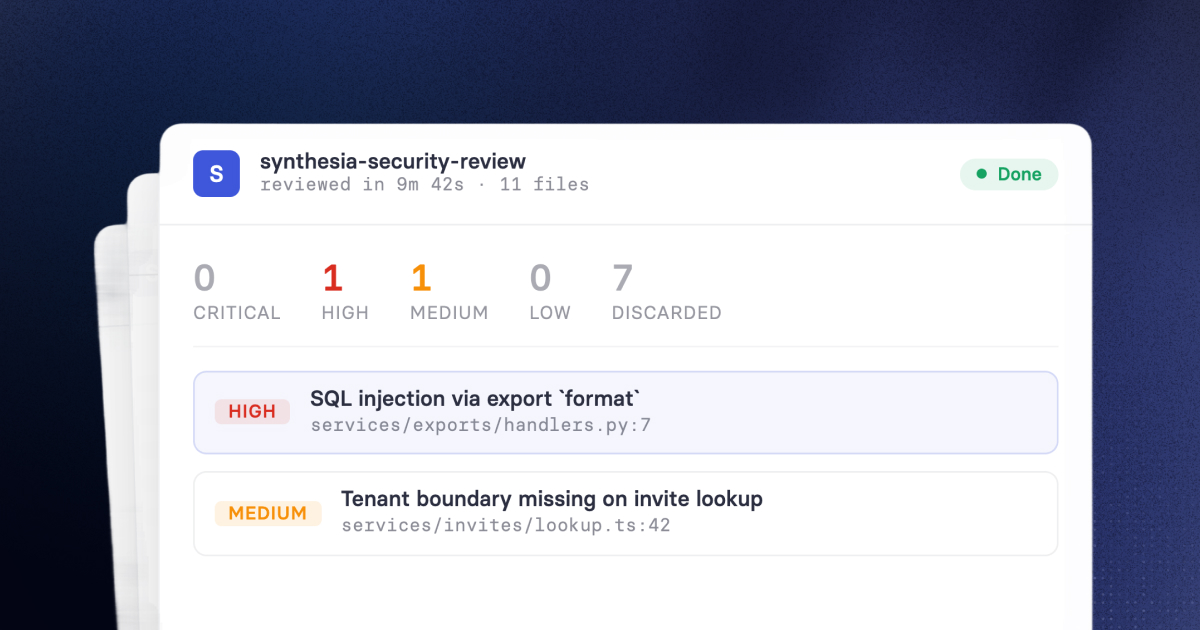
The Problems
Agents All The Way Down
If you're like us when we started, you've probably already tried to give AI agents some of the above types of context already.
Maybe you've pulled some docs together that describe your architecture and used a RAG approach to give an LLM the context it needs? Maybe you've codified some of your risk appetite into prompts you've created? Maybe you've even written detailed agentic skills for specific kinds of security review?
Yup, we did all of that too, and if we had only one or two agentic tools or workflows, that might have been fine. However, we wanted multiple agentic workflows with us in the loop, covering document review, threat modelling and PR review, and ranging from fully automated workflows to agent-assisted manual review.
And that's when things started falling apart. Every agent had a slightly different version of reality. One had an updated threat model. Another was still working from an architecture overview that predated a significant refactor. When a risk decision changed, you had to remember everywhere it had been referenced and update each one manually.
In practice, you didn’t. What started as cool examples of what could be done became less valuable and far too much maintenance.
So we knew we needed to centralise our security context and make it consumable by any agent we were running, wherever and however we ran it. That's not a technical insight. It's basic information hygiene, but it took hands-on experience to appreciate how much it mattered at scale.
Context Has A Cost
Then there's the context window challenge. Yes, you could dump all this context into a single file or a couple of large files and load it into the agent's context window on every run, but that is going to make you sad quickly:
- Context window size: Yes, newer models have increasingly large context windows, but if you want them to do iterative, complex analysis, spending 50% of that window on context that might never be used is asking for trouble.
- Token cost: Large context windows are expensive. If you just need an agent to take a quick, specific action, you are overpaying. And if you want the latest reasoning models because they do a better job, you amplify the cost even further.
- Signal dilution: The more irrelevant content you include, the harder it is for the agent to surface what matters for the specific code it is reviewing.
- Maintenance burden: Updating a large doc is painful. We all like to think we will do it, but we do not.
So the challenge was not just centralising our four context types. It was ensuring we could deliver the right slice of context to the right agent at the right time, without blowing the budget or burying the signal.
How We Approached It
We knew we wanted to give the AI agent right-sized, right-scoped context for the task at hand, and we wanted this to be centrally accessible to any agentic workflow we run.
So, perhaps unsurprisingly, we chose to create this context in a dedicated GitHub repo called (rather unimaginatively) appsec-security-context.
Why GitHub?
You likely already have wikis and tools for docs and runbooks, and many have APIs or MCP servers. We could have used those, but GitHub was the clear winner for us:
- It's accessible to almost any type of AI agent. Any agent that touches code will already be able to access GitHub. And coding agents are trained to understand it. This is one area where the agent just "gets it".
- Change control and versioning come for free. Every update to the context is a PR, with mandatory review, attribution, history, and the ability to roll back. For a resource that agents actively use to make security decisions, that audit trail matters.
- It keeps AppSec ownership clear. The repo is ours. PRs to it come to us. It does not get mixed in with product documentation or slowly changed by engineers who mean well but do not have the full risk picture.
What’s In The Repo?
Thinking back to the four areas we outlined earlier that define context. We wanted a way to codify all this, and we landed on two core context types:
- Codebase Context: Architectural Context, Code Patterns and Conventions
- Threat Model Context: Threat Models, Risk Appetite and Accepted Risks
Codebase Context
In our previous post on PR scanning, we described why security context should be kept separate from codegen context. They pull in opposite directions: codegen context encourages following existing patterns, while security review often needs you to challenge them.
Codebase context captures the security expectations for a specific service. Each service/repo gets its own folder under codebase/, and the context is written in layers that match the repo structure, so an AI agent only loads what’s relevant to the code it’s reviewing.
.png)
Each layer has a specific job that incrementally builds context. This solves the context cost problem we mentioned earlier.
The agent only loads files relevant to the code it's actually reviewing. A PR touching the auth module gets auth context. It doesn't get the billing module's false positive guidance or the event handler's trust boundary rules. Right-sized, right-scoped, every time.
Threat Model Context
We did not cover this in the previous blog post, and it is always a contentious topic. What is a threat model? The simplest answer is that it’s whatever helps you reason about risk and evaluate whether you have built the right controls.
For us, the key thing threat model context needed to solve was giving agents access to the reasoning, not just the conclusions. Not just "this risk is accepted", but why, under what assumptions, and what would need to change for that decision to be revisited.
That last part matters more than it might seem. For example, an AI agent that knows a risk was accepted on the assumption that a feature is an enterprise-only feature, should behave differently when it sees a PR opening that feature up to everyone.
But here's where it gets interesting. A threat model written for a human and a threat model written for an agent aren't the same thing, and trying to make one serve both purposes is where most threat modelling approaches fall down.
The human version is structured around reasoning, judgement, and readability. The agent version is structured for consumption, not comprehension. Same source of truth, fundamentally different shape.
So we create two, with both files live in the repo under threat-models/, one pair per feature.
The human version gets updated by the AppSec team as the feature evolves, new findings come in, or accepted risk decisions change. Designed to be read, debated, and updated by security engineers. It gives you the full picture and the reasoning behind every decision; with five key sections.
The agent version is automatically derived from the human version but organised around what's actionable for an AI agent.
.png)
How Do We Create These?
At first, it took a lot of trial and error. We wrote first passes based on what we thought should be included, then tested them across different AI agent workflows to see what worked, what didn’t, and iterated.
Once we landed on the right format, content, and level of detail, things got a lot easier. Because, hey, “there’s a skill for that!”. Or more precisely, “we wrote a skill for that”.
Each context type has a generation skill, focused less on one-shot creation and more on iterating the context over time. You don’t need to worry about formatting or remembering everything that should be included, you keep a human in the loop to review what the AI agent suggests, correct it, add or remove key details, and let the AI agent do the heavy lifting.
The codebase context skill takes a link to a GitHub repo. It clones it, and makes a first pass at pulling out the key security context we care about, validates these with you, highlights gaps that might be known risks, and allows you to update with information on known anti-patterns or contextual risk rating information. With a little back-and-forth, you can usually get solid context for a repo in under half an hour.
Similarly, the threat model skill takes a link to a product requirements or design doc, identifies actors and trust boundaries, and walks you through a threat-by-threat review. It suggests likelihood and impact ratings, flags missing controls, and asks which gate each threat needs to be resolved by. At the end, it writes both files and drops a comment on the Linear issue linking to the output. An engineer who’s given the docs a first pass read can usually produce a solid, structured human and agent threat model in under half an hour, instead of starting from a blank page.
What Workflows Use This Context?
We're currently using this security context across three distinct agents, and the difference it makes is visible in all. We'll cover each briefly here and plan to go deeper on each in follow-up posts.
Doc Reviewer
What it does
- Monitors our docs platform + key Slack threads for product/engineering docs that need AppSec review. Helps us scale without having to constantly watch for new docs.
How centralised context helps
- Threat model context: checks whether existing threat models cover the proposed feature, and whether changes could affect threats, assumptions, or risk ratings.
- Codebase context: flags where the design follows (or deviates from) expected security patterns.
What we learned
- Without context, doc-review agents fail because docs assume shared background knowledge.
- Threat modelling shouldn’t be fully auto-generated: the agent identifies what needs attention, but the threat modelling stays human-in-the-loop.
- Every review improves the next one (for every agent) immediately.
PR Scanning
What it does
- Runs an AI-powered security review on every PR before it merges.
- Pipeline details in our previous post.
How centralised context helps
- Findings became much more consistent across runs (lower variance).
- False positives dropped sensibly.
- Component-level false-positive guidance was the biggest driver of improvement.
What we learned
- Quality and formatting of output is key to avoid PR input bloat and loose engineer interest.
Backstop PR Scanning
What it does
- Scans every merged PR daily (in addition to pre-merge scanning). Performs not just codebase context scans, but also evaluates each PR against our threat models.
How centralised context helps
- Pending controls: visibility into when threat-model controls are actually implemented in PRs.
- Scope drift: Early warning when a PR changes areas covered by a threat model but wasn’t in the original design doc.
- Assumption changes: Flags when a PR changes a condition a risk decision was based on.
What we learned
- This gives way more value that we expected from a scaling perspective as it gives realtime insight into changes in scope or assumptions that typically resulted in late findings.
- Running this as a backstop rather than pre-merge allows the AI agents more time for review, without impacting on PR merge speed.
- Getting the AI Agent to select the “most applicable” threat model is tricky when evaluating just a single PR in isolation.
Where We're Heading
Right now, as noted context is largely hand-authored. That works, but it's the most obvious bottleneck as the number of services and agents grows.
The next step is closing the loop: using the agent's own findings to prompt updates to the context.
If an agent keeps raising the same accepted risk across multiple PRs, that's a signal the context file needs updating. If it flags something that turns out to be a genuine architectural issue, that probably belongs in a threat model.
But the bigger step is making context generation itself more automated. We're building a tool we're calling Panorama for this.
The idea is an LLM-based scanner that continuously monitors our repositories and keeps additional context information current automatically. Things like which services are active in production, what categories of customer data each service handles, when the codebase last changed significantly, what dependencies are in use. The kind of factual, observable information that's genuinely tedious to maintain by hand but critically important for an agent to have.
The goal is a security context layer that improves over time and largely maintains itself, rather than a static set of docs that gradually becomes wrong and eventually misleading.
Hand-authored context stays valuable for the nuanced stuff: risk decisions, accepted exceptions, threat model reasoning, where human judgement is the point. Panorama takes on the burden of keeping the factual baseline accurate.
We'll be covering Panorama, the Doc Reviewer, and the PR Backstop Scanning in more detail in follow-up posts.
Build Your Own
Getting agents to do valuable security work isn't primarily a model problem, it's a context problem. Nothing we've built here is technically difficult. The value is in the thinking, not the tooling.
And the good news is that AppSec teams already know how to think about this. They do it every time they bring someone new onto the team.
You'd onboard your next AppSec engineer with architectural context, threat models, and a clear picture of what normal looks like. Do the same for your agents.
A few principles that have held across everything we've built:
- Keep context files short and opinionated. Don't try to document everything. Capture the decisions, the gotchas, and the risk positions that would take an agent the longest to figure out on its own.
- False positive guidance is as important as vulnerability guidance. An agent that knows what not to flag is as valuable as one that knows what to flag. Document intentional patterns explicitly.
- Treat threat models as living documents. A threat model written at launch and never touched again is worse than useless. Build a lightweight update process tied to significant changes or new features.
- Be explicit about accepted risks. Don't just say "this is accepted." Say why, and under what conditions you'd revisit it. Give the agent the reasoning, not just the conclusion.
- Own the context repo like a product. It has users. It has quality standards. It needs to be reviewed and updated. Treat neglecting it the same way you'd treat letting your threat model go stale.
Point a coding agent at this post and have it draft a starting set of context files for your most critical service. Then iterate.
The blank page problem is the hardest part, and that's exactly what the AI agents are there to help solve.
Máirtín O'Sullivan is a Security Engineer in the application security team at Synthesia, building AI-powered tooling and agentic workflows that help engineering teams ship securely at scale.